





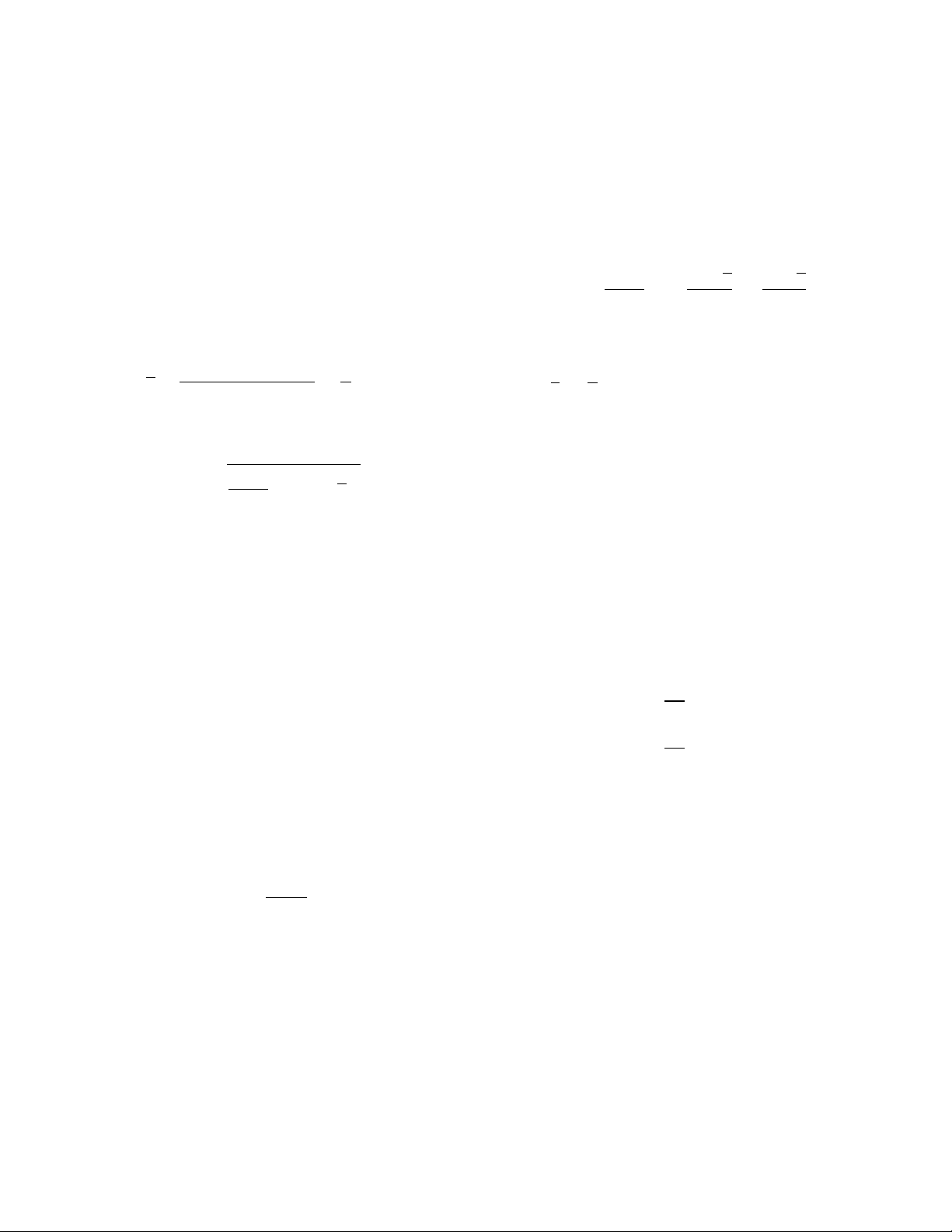
TABLES AND FORMULAS FOR MOORE
Basic Practice of Statistics
Exploring Data: Distributions
•Look for overall pattern (shape, center, spread)
and deviations (outliers).
•Mean (use a calculator):
x=x1+x2+···+xn
n=1
n!xi
•Standard deviation (use a calculator):
s="1
n−1!(xi−x)2
•Median: Arrange all observations from smallest
to largest. The median Mis located (n+ 1)/2
observations from the beginning of this list.
•Quartiles: The first quartile Q1is the median of
the observations whose position in the ordered
list is to the left of the location of the overall
median. The third quartile Q3is the median of
the observations to the right of the location of
the overall median.
•Five-number summary:
Minimum, Q1, M, Q3,Maximum
•Standardized value of x:
z=x−µ
σ
Exploring Data: Relationships
•Look for overall pattern (form, direction,
strength) and deviations (outliers, influential
observations).
•Correlation (use a calculator):
r=1
n−1!#xi−x
sx$%yi−y
sy&
•Least-squares regression line (use a calculator):
ˆy=a+bx with slope b=rsy/sxand intercept
a=y−bx
•Residuals:
residual = observed y−predicted y=y−ˆy
Producing Data
•Simple random sample: Choose an SRS by giv-
ing every individual in the population a numer-
ical label and using Table B of random digits to
choose the sample.
•Randomized comparative experiments:
Random
Allocation
!
!"
#
#$
Group 1
Group 2
%
%
Treatment 1
Treatment 2
#
#$
!
!"
Observe
Response
Probability and Sampling
Distributions
•Probability rules:
•Any probability satisfies 0 ≤P(A)≤1.
•The sample space Shas probability P(S) =
1.
•For any event A,P(Adoes not occur) =
1−P(A)
•If events Aand Bare disjoint, P(Aor B) =
P(A) + P(B).


