


Lecture 17: EM
TTIC 31020: Introduction to Machine Learning
Instructor: Greg Shakhnarovich
TTI–Chicago
November 3, 2010
Lecture 17: EM TTIC 31020














Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Community
Ask the community for help and clear up your study doubts
Discover the best universities in your country according to Docsity users
Free resources
Download our free guides on studying techniques, anxiety management strategies, and thesis advice from Docsity tutors
An overview of the em algorithm for gaussian mixture models, as presented in lecture 17 of the ttic 31020: introduction to machine learning course. The em algorithm is a method for maximizing the likelihood of a model given observed data, and it is particularly useful for mixture models, where the data can be assumed to come from a mixture of multiple distributions. The basic steps of the em algorithm, including initialization, the e-step and m-step, and the convergence of the algorithm. It also discusses the use of the em algorithm for missing data and the importance of regularization to prevent overfitting.
Typology: Lecture notes
1 / 22

This page cannot be seen from the preview
Don't miss anything!
TTIC 31020: Introduction to Machine Learning
Instructor: Greg Shakhnarovich
TTI–Chicago
November 3, 2010
Initialize: random μoldc , Σoldc , πoldc = 1/k, for c = 1,... , k. Iterate until convergence: E-step estimate responsibilities:
γic =
πcold N
xi; μoldc , Σoldc
∑k l=1 π old l N^
xi; μoldl , Σoldl
M-step re-estimate mixture parameters:
̂ πnewc =
i=
γic,
̂ μnewc =
i=1 γic
i=
γicxi,
Σ̂ newc = (^) ∑^1 N i=1 γic
i=
γic(xi − μ̂ newc )(xi − ̂μnewc )T^.
Observed data X, hidden variables Z.
Initialize θold, and iterate until convergence: E-step: Compute the expected complete data log-likelihood as a function of θ.
Q
θ; θold
= Ep(Z | X,θold)
log p(X, Z; θ) | X, θold
M-step: Compute
θnew^ = argmax θ
θ; θold
Suppose some of the data is missing.
Examples:
E-step: compute posterior and expectation only over missing data.
M-step: maximize likelihood over complete data, i.e. observed and missing.
Initial guess: θold^ = [0, 0 , 1 , 1]T^ i.e., μ = 0 , Σ = I. After some calculus:
Q(θ; θold) =
i=
N (xi; 0 , I)− 1 + μ^21 2 σ^21
(4 − μ 2 )^2 2 σ^22
−log 2πσ 1 σ 2.
Maximizing w.r.t. θ we get
θnew^ = [0. 75 , 2 , 0. 938 , 2]T
After three iterations, converges to θ = [1, 2 ,. 667 , 2]T
Ultimately, we want to maximize likelihood of the observed data θ∗^ = argmax θ
log p(X; θ).
Let log p(t)^ be log p(X; θnew) after t iterations.
Can show (not today):
log p(0)^ ≤ log p(1)^ ≤... ≤ log p(t)^...
log p(0)^ ≤ log p(1)^ ≤... ≤ log p(t)^...
The idea of the proof:
EM monotonically increases likelihood of the observed data.
Typical with mixture models, need to compute log p(x ; θ) = log
∑k c=1 πc^ p(x;^ θc) Problem: underflow (especially in high-dimensional spaces)
x=[-2000 -2006]; log(sum(exp(x))) Warning: Log of zero. ans = -Inf
Observation: a = log[exp(a)] = log[exp(a + B)] − B. Set a constant B so that the highest p(x; θc) saturates positive precision on your machine.
B=700-max(logp);log(sum(exp(x+B)))-B ans = -2.0000e+
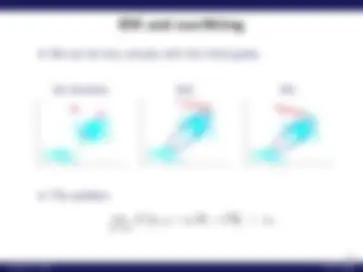
We can be very unlucky with the initial guess.
1st iteration 2nd 4th
−4−6 −4 −2 0 2 4 6 8
−
0
2 4
6
8
10
12
−4−6 −4 −2 0 2 4 6 8
−
0
2
4
6
8
10
−4−6 −4 −2 0 2 4 6 8
−
0
2 4
6
8
10
12
The problem:
lim σ^2 → 0
x; μ = x, Σ = σ^2 I
Impose a prior on θ.
Instead of maximizing the likelihood in the M-step, maximize the posterior:
θnew^ = argmax θ
Ep(Z|X;θ)
log p(X, Z; θ)|X; θold
A common prior on a covariance matrix: the Wishart distribution
p(Σ; S, n) ∝
|Σ|n/^2
exp
Tr
Intuition: S is the covariance of n “hallucinated” observations.
So far we have assumed known k. Idea: select k that maximizes the likelihood.
−6 −4 −2 0 2 4 6 8
−
0
2
4
6
8
k
log
p
So far we have assumed known k. Idea: select k that maximizes the likelihood.
−6 −4 −2 0 2 4 6 8
−
0
2
4
6
8
−6 −4 −2 0 2 4 6 8
−
0
2
4
6
8
k
log
p
So far we have assumed known k. Idea: select k that maximizes the likelihood.
−6 −4 −2 0 2 4 6 8
−
0
2
4
6
8
−6 −4 −2 0 2 4 6 8
−
0
2
4
6
8
−6 −4 −2 0 2 4 6 8
−
0
2
4
6
8
−6 −4 −2 0 2 4 6 8
−
0 2
4 6
8
−8 −6 −4 −2 0 2 4 6 8
−2^0
2 46
8 10
k
log
p
Place a separate, very narow Gaussian component on every training example.
This solution yields infinite log-likelihood!
We need a criterion to penalize such models.
Occam’s razor: try to find the simplest among all possible explanations.
Reminder: AIC
max θ
log p(X; θ) −
|θ| 2
where |θ| stands for the number of parameters in θ.