




CS333 Lecture Notes
Syntax
Fall 2019
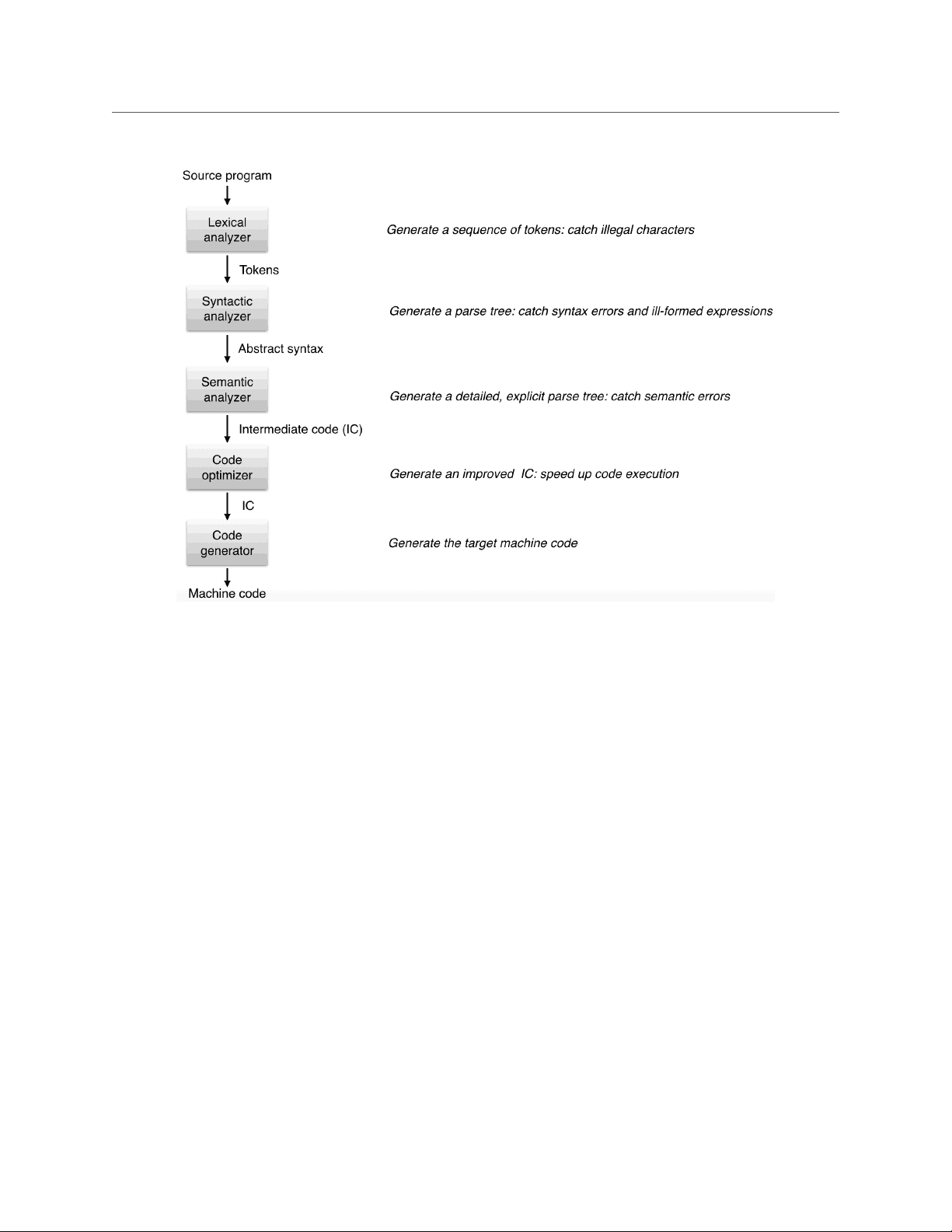
Stages of Compilation
•Lexical analysis
- takes source file as input
-generate a sequence of valid tokens
- character sequences that do not form valid tokens are discard, after generating an
error message
•Syntactic analysis
- takes a sequence of tokens as input
- parses the token sequence, constructs a parse tree/abstract syntax tree according to
the grammar
- check syntax errors and ill-formed expressions
•Semantic analysis
- takes parse tree/abstract syntax tree as input
-generate intermediate code (more explicit, detailed parse tree where operators will
generally be specific to the data type they are processing)
- catch semantic errors like undefined variables, variable type conflicts, and implicit
conversions
•Code optimization
- take the intermediate code as input
- identify optimizations that speed up code execution without changing the program
functionality
•Code generator
- converts the intermediate code into machine code
- machine code is tailored to a specific machine, while intermediate code is general
across platforms
