


Randal E. Bryant
Carnegie Mellon University
CS:APP2e
CS:APP Chapter 4
Computer Architecture
Pipelined
Implementation
Part I
http://csapp.cs.cmu.edu


















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Community
Ask the community for help and clear up your study doubts
Discover the best universities in your country according to Docsity users
Free resources
Download our free guides on studying techniques, anxiety management strategies, and thesis advice from Docsity tutors
Implementing Stalling ,Pipeline Register Modes, Data Forwarding, Bypass Paths ,Forwarding Priority ,Implementing Forwarding, Handling Mispredictions
Typology: Slides
1 / 32

This page cannot be seen from the preview
Don't miss anything!
CS:APP2e
Overview
General Principles of Pipelining
Goal
Difficulties
Creating a Pipelined Y86 Processor
Rearranging SEQ
Inserting pipeline registers
Problems with data and control hazards
Computational Example
System
Computation requires total of 300 picoseconds
Additional 20 picoseconds to save result in register
Must have clock cycle of at least 320 ps
Combinational logic
e g
300 ps 20 ps
Clock
Delay = 320 ps Throughput = 3.12 GIPS
3-Way Pipelined Version
System
Divide combinational logic into 3 blocks of 100 ps each
Can begin new operation as soon as previous one passes through stage A.
Overall latency increases
e g
Clock
Comb. logic A
e g
Comb. logic B
e g
Comb. logic C
100 ps 20 ps 100 ps 20 ps 100 ps 20 ps
Delay = 360 ps Throughput = 8.33 GIPS
Operating a Pipeline
Time
0 120 240 360 480 640
Clock
R e g
Clock
Comb. logic A
R e g
Comb. logic B
R e g
Comb. logic C
100 ps 20 ps 100 ps 20 ps 100 ps 20 ps
R e g
Clock
Comb. logic A
R e g
Comb. logic B
R e g
Comb. logic C
100 ps 20 ps 100 ps 20 ps 100 ps 20 ps
R e g
R e g
R e g
100 ps 20 ps 100 ps 20 ps 100 ps 20 ps
Comb. logic A
Comb. logic B
Comb. logic C
Clock
R e g
Clock
Comb. logic A
R e g
Comb. logic B
R e g
Comb. logic C
100 ps 20 ps 100 ps 20 ps 100 ps 20 ps
Limitations: Nonuniform Delays
Throughput limited by slowest stage
Other stages sit idle for much of the time
Challenging to partition system into balanced stages
e g
Clock
e g
Comb. logic B
e g
Comb. logic C
50 ps 20 ps 150 ps 20 ps 100 ps 20 ps
Delay = 510 ps Throughput = 5.88 GIPS
Comb. logic A
Time
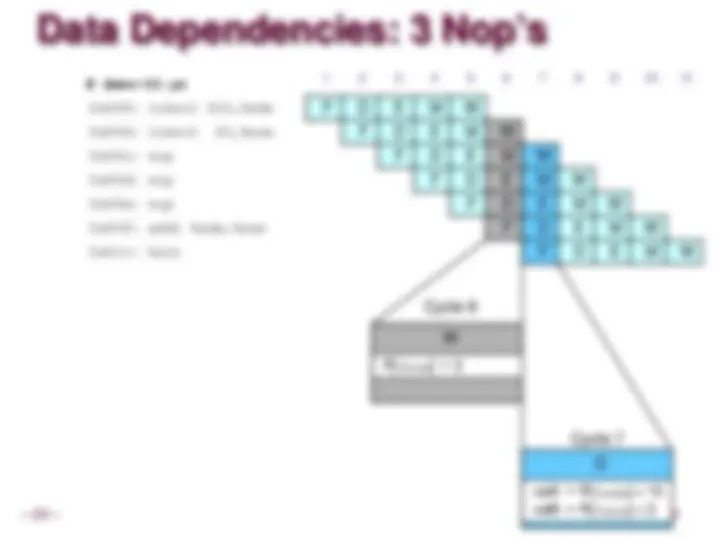
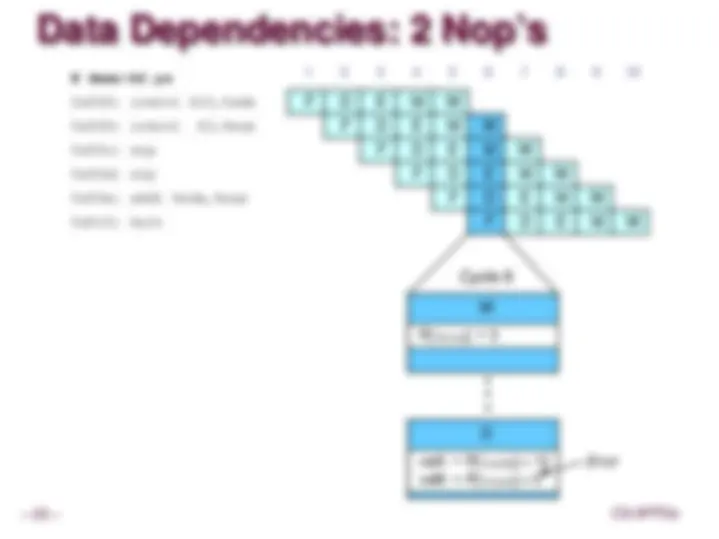
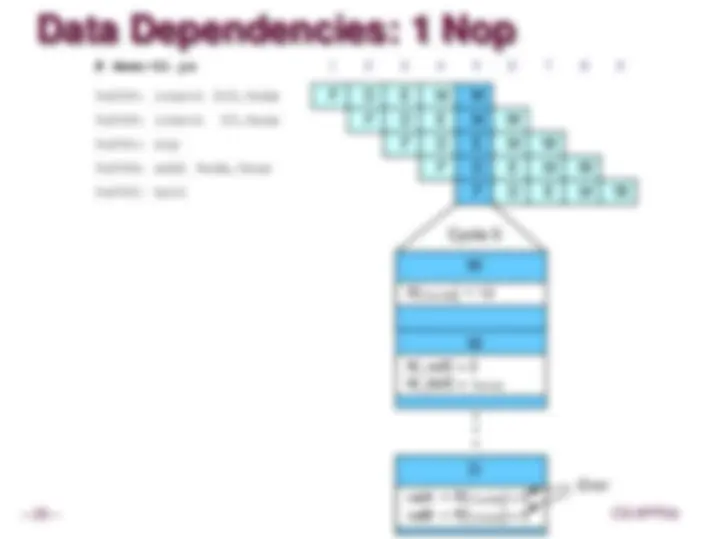
Data Dependencies
System
Each operation depends on result from preceding one
Clock
Combinational logic
e g
Time
Data Hazards
Result does not feed back around in time for next operation
Pipelining has changed behavior of system
e g
Clock
Comb. logic A
e g
Comb. logic B
e g
Comb. logic C
Time
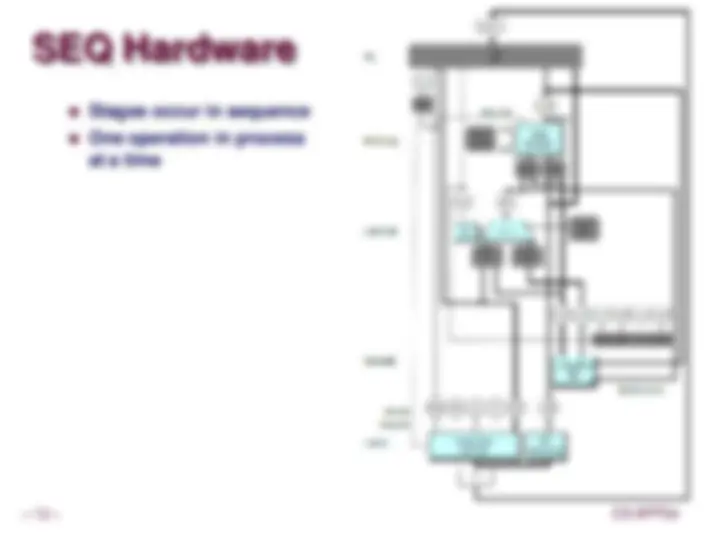
SEQ Hardware
SEQ+ Hardware
PC Stage
Processor State
Pipeline Stages
Fetch
Select current PC
Read instruction
Compute incremented PC
Decode
Read program registers
Execute
Operate ALU
Memory
Read or write data memory
Write Back
Update register file
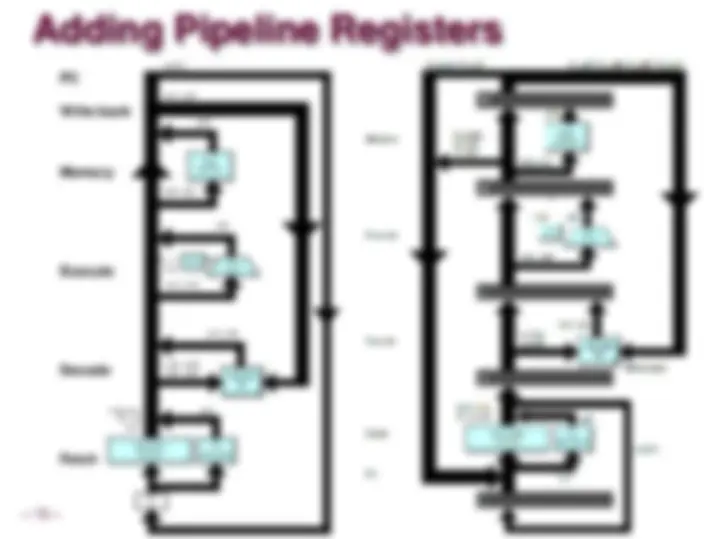
PIPE- Hardware
Pipeline registers hold intermediate values from instruction execution
Forward (Upward) Paths
Values passed from one stage to next
Cannot jump past stages
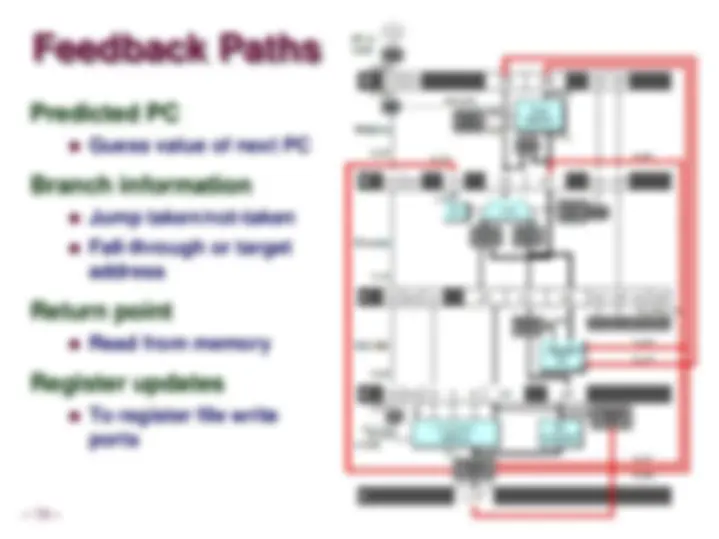
Feedback Paths
Predicted PC
Guess value of next PC
Branch information
Jump taken/not-taken
Fall-through or target address
Return point
Read from memory
Register updates
To register file write ports
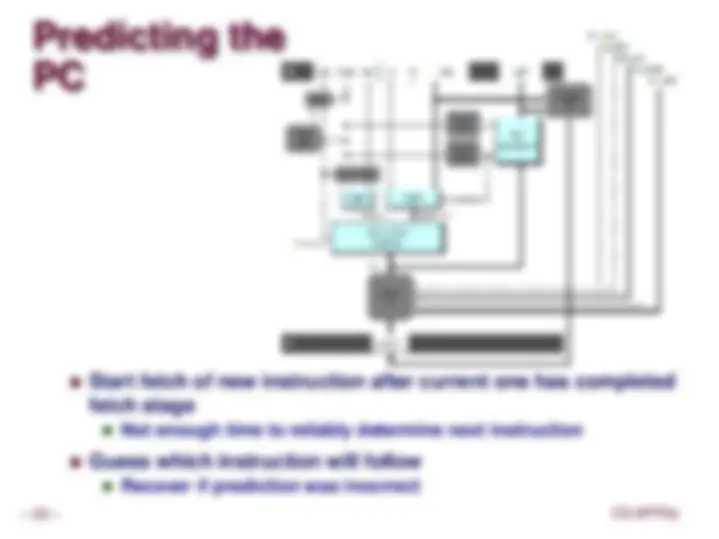
Predicting the
PC
Start fetch of new instruction after current one has completed fetch stage
Guess which instruction will follow