Download Intelligent Memory Access with PIGLET and Threadlets - Prof. Peter Kogge and more Lab Reports Computer Science in PDF only on Docsity!
Memory Interface Programming: IWIA – January 12-13, 2004
Of Piglets and Threadlets:
Architectures for Self-Contained,
Mobile, Memory Interface
Programming
Peter M. Kogge
McCourtney Prof. Of CS & Engr, Assoc. Dean for Research
IBM Fellow (Retired)
University of Notre Dame
Memory Interface Programming: IWIA – January 12-13, 2004
The Memory Wall
Performance of conventional systems limited by
Large numbers of high latency events
Particularly for shared memory systems
And particularly for non-temporally intensiveapplications
Examples:
Remote load/stores
Synchronization Operations
Sparse gather/scatter
And more ...
Memory Interface Programming: IWIA – January 12-13, 2004
Assumptions
Massively parallel shared memory system
Where “memory” is PIM-enhanced
Each memory chip = collections of
Memory macros
Local processing units
To access memory, a processor
Assembles a parcel
With appropriate embedded code
And launches thru interconnection network
To target memory location
And associated code becomes a thread on localPIM processor
Memory Interface Programming: IWIA – January 12-13, 2004
Slide 5
IWIA04.PPT
“Processing-In-Memory”
High density memory on same chipwith high speed logic
Very fast access from logic to memory
Very high bandwidth at each access
Up to 2048 bits in < 10 ns
ISA/microarchitecture designed toutilize high bandwidth
Tile chip with “memory+logic” nodes
Interconnect
incoming
parcels
outgoing
parcels
Parcel = Object Address + Method_name + Parameters
Performance Monitor
Wide Register File
Wide ALUs
Permutation NetworkThread State Package
Global Address Translation Parcel Decode and Assembly
Broadcast Bus
Row Decode Logic
Sense Amplifiers/LatchesColumn Multiplexing
MemoryArray 1 “Full Word”/Row 1 Column/Full Word
Bit
“Wide Word” Interface
Address
A S A P
A Memory/Logic
Node
Tiling a Chip
Memory Interface Programming: IWIA – January 12-13, 2004
An “All-PIM” Supercomputer
PIM PIM PIM PIM PIM PIM PIM PIM
PIM PIM PIM PIM PIM PIM PIM PIM
PIM PIM PIM PIM PIM PIM PIM PIM
PIM PIM PIM PIM PIM PIM PIM PIM
Interconnection
Network
PIM Cluster
PIM Cluster
“Host”
PIM Cluster
I/O
A “PIM Cluster”
A “PIM DIMM”
Memory Interface Programming: IWIA – January 12-13, 2004
PIM Lite
“Looks like memory” at Interfaces
ISA: 16-bit multithreaded/SIMD
“Thread” = IP/FP pair
“Registers” = wide words in frames
Multiple nodes per chip
1 node logic area ~ 10.3 KB SRAM(comparable to MIPS R3000)
TSMC 0.18u 1-node in fab now
3.2 million transistors (4-node)
Thread Queue
Frame
Memory
Instr
Memory
ALU
Data
Memory
Write-
Back Logic
Parcel in (via chip data bus)
Parcel out (via chip data bus)
memory interconnect network
Memory interconnect network
Memory
CPU
PIM
memory interconnect network
Memory interconnect network
Memory
CPU
PIM
Memory Interface Programming: IWIA – January 12-13, 2004
Nominal PIGLET Parcel Formats
E[0]
E[1]
E[2]
E[3]
A
D
R
F,S,PC C[4]...C[15]
E[4]
E[5]
E[6]
E[7]
E[8]
E[9]
E[10]
E[11]
E[12]
E[13]
E[14]
E[15]
E[16]
E[17]
E[18]
E[19]
E[20]
E[21]
E[22]
E[23]
E[24]
E[25]
E[26]
E[27]
E[28]
E[29]
E[30]
E[31]
W[0]W[1]W[2]W[3]W[4]W[5]W[6]W[7]
E[i] contains C[16+16i] through C[31+16i]U is made up of W[0] through W[7]
Present only in extended formatsPresent only in 2304 bit formats
256 bits wide
Baseline Threadlet Registers
A: Target Address of this accessD: Associated Data WordR: Typically Address for return info
Memory Interface Programming: IWIA – January 12-13, 2004
PIGLET-0 ISA
Instructions in multiples of 4 bits
Simple “Accumulator” style
D <= D op Memory[A]
With access to rest of parcel as
Either registers with special function(eg. R)
Or “local memory array” (eg. Payload)
Key new instructions
MOVE
thread to address specified by A
SPAWN
a new threadlet/parcel
LOCK
out &
RELEASE
access to a local location
SUSPEND
self to local memory
AWAKEN
some suspended thread in local memory
Memory Interface Programming: IWIA – January 12-13, 2004
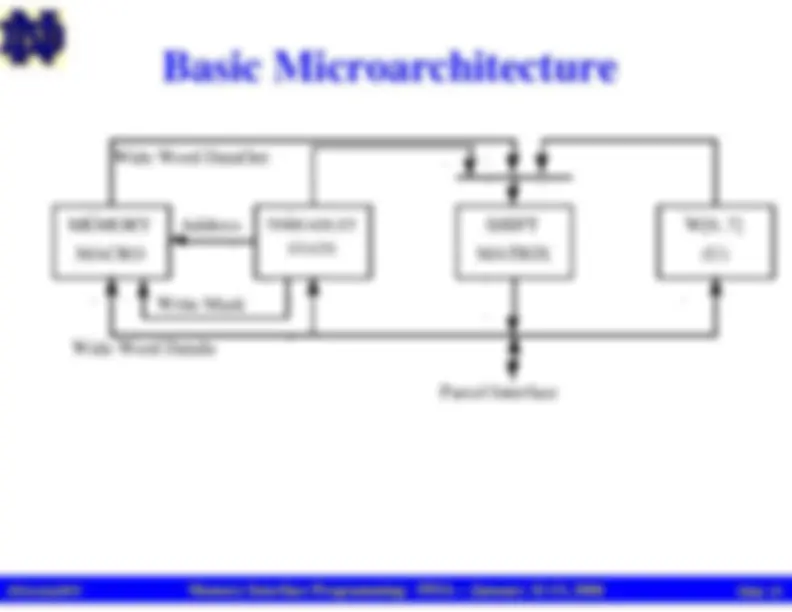
Basic Microarchitecture
MEMORY
MACRO
THREADLET
STATE
SHIFT
MATRIX
W[0..7]
(U)
Wide Word DataOut
Wide Word DataIn
Write Mask
Address
Parcel Interface
Memory Interface Programming: IWIA – January 12-13, 2004
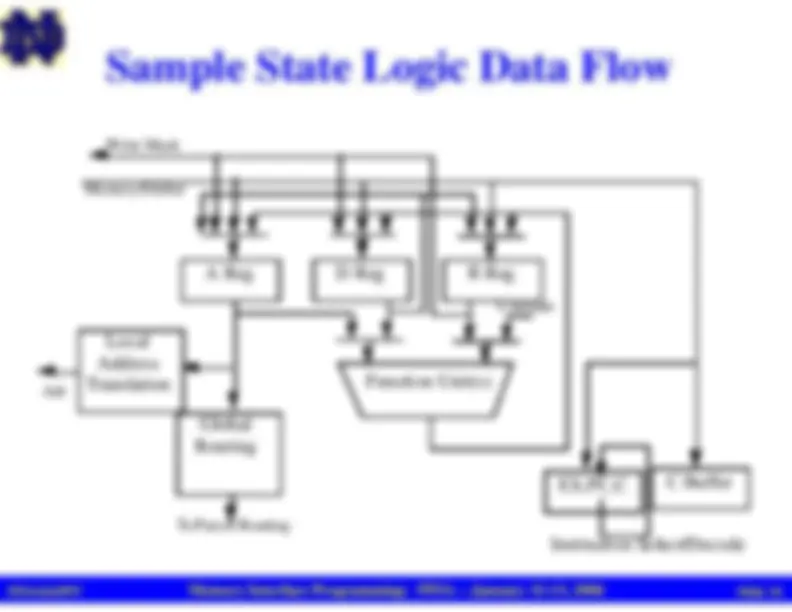
Sample State Logic Data Flow
A Reg
D Reg
R Reg
Local
Address
Translation
Global
Routing
Function Unit(s)
Constant
To Parcel Routing
Memory/Shifter
Write Mask
Adr
C Buffer
F,S,PC,C
Instruction Select/Decode
Memory Interface Programming: IWIA – January 12-13, 2004
More Exotic Parcel Functions
The “Background” Ones •
Garbage Collection: reclaim memory
Load Balancing: check for over/under load &suggest migration of activities
Introspection: look for livelock, deadlock, faultsor pending failures
Key attributes of all of these
Independent of application programs
Inherent memory orientation
Significant possibility of mobility
Memory Interface Programming: IWIA – January 12-13, 2004
Parcels for “Dumb” Operations
Function
A Register
R Register
D Register
Payload
Program Size
Single Word Read
Target
Address
Return
Address
None
No
24 bits
Single Word Read Return
Return
Address
Data Word
None
No
Part of Above
Single Word Write
Target
Address
Acknowledge
Address
Data Word
No
40 bits
Single Word Write
Acknowledge
Acknowledge
Address
None
None
No
Part of Above
Cache Read
Target
Address
Return
Address
None
No
32 bits
Cache Read Return
Target
Address
None
None
Yes
Part of Above
Cache Write
Target
Address
Acknowledge
Address
None
Yes
40 bits
Cache Write Acknowledge
Target
Address
None
None
No
Part of Above
Bottom Line: “Dumb” Operations = “Simple” Programs
Memory Interface Programming: IWIA – January 12-13, 2004
Example: AMO
AMO = Atomic Memory Operation
Update some memory location
With guaranteed no interference
And return result
Parcel Registers: A=Address, D=Data, R=Return Address
Sample Code:
MOVEL1: LOCK & LOADOPSTORE & RELEASE L1SWAPRAMOVE ASTOREQUIT
Atomic Update “At the Memory”
Return Result
Bottom Line: 2 network transactions rather than up to 6!
Memory Interface Programming: IWIA – January 12-13, 2004
IWIA04.PPT
Vector Add (Z[I]=X[I[+Y[I]) via
Traveling Threads
X
M
E
M
O
R Y
X
M
E
M
O R Y
X
M
E
M
O
R Y
X
M
E
M
O R Y
Type 1
Y
M
E
M
O
R Y
Y
M
E
M
O R Y
Y
M
E
M
O
R Y
Y
M
E
M
O
R Y
Type 2 Type 3
Accumulate Q
X’s in payload
Spawn type 2s
Fetch Q
matching Y’s,
add to X’s,
save in payload,
store in Q Z’s
Z
M
E
M
O R Y
Z
M
E
M
O
R Y
Z
M
E
M
O R Y
Z
M
E
M
O R Y
Stride thru Q elements
Transaction Reduction factor: •
1.66X (Q=1)
10X (Q=6)
up to 50X (Q=30)